
Archiving your Meta accounts

This is the third in a series of posts about divesting your social life from Meta. In previous posts I made a case for why I’m leaving Meta (and other Big Social platforms), and how to start the process of leaving.
Before you delete your Facebook, Instagram, and Threads accounts, I recommend downloading an archive of your data first. Even if you're not ready to divest from Meta, having archives is still a good idea!
This guide is somewhat opinionated, I recommend that you request as much data as Meta will give you, even for stuff that you don’t think you need. I want to understand the gaze of corporate surveillance to the fullest extent possible. I'm also suggesting that you request it in machine-readable JSON format, to make it more useful to explore in the future.
Requesting an archive
These steps assume that you're using a computer with a web browser, not a phone. The official Facebook documentation does include guidance on how to request account data from a mobile app. This guide will no doubt become obsolete as Facebook redesigns its pages and restructures how settings work, but as of now this is how things work.
Start at the Meta Accounts Center and then Download your information.
Next click on the button labeled Download or transfer information.
Select all your accounts.
I do have a Threads account and I wasn’t offered that as an option, it just gets bundled in with the Instagram archive.
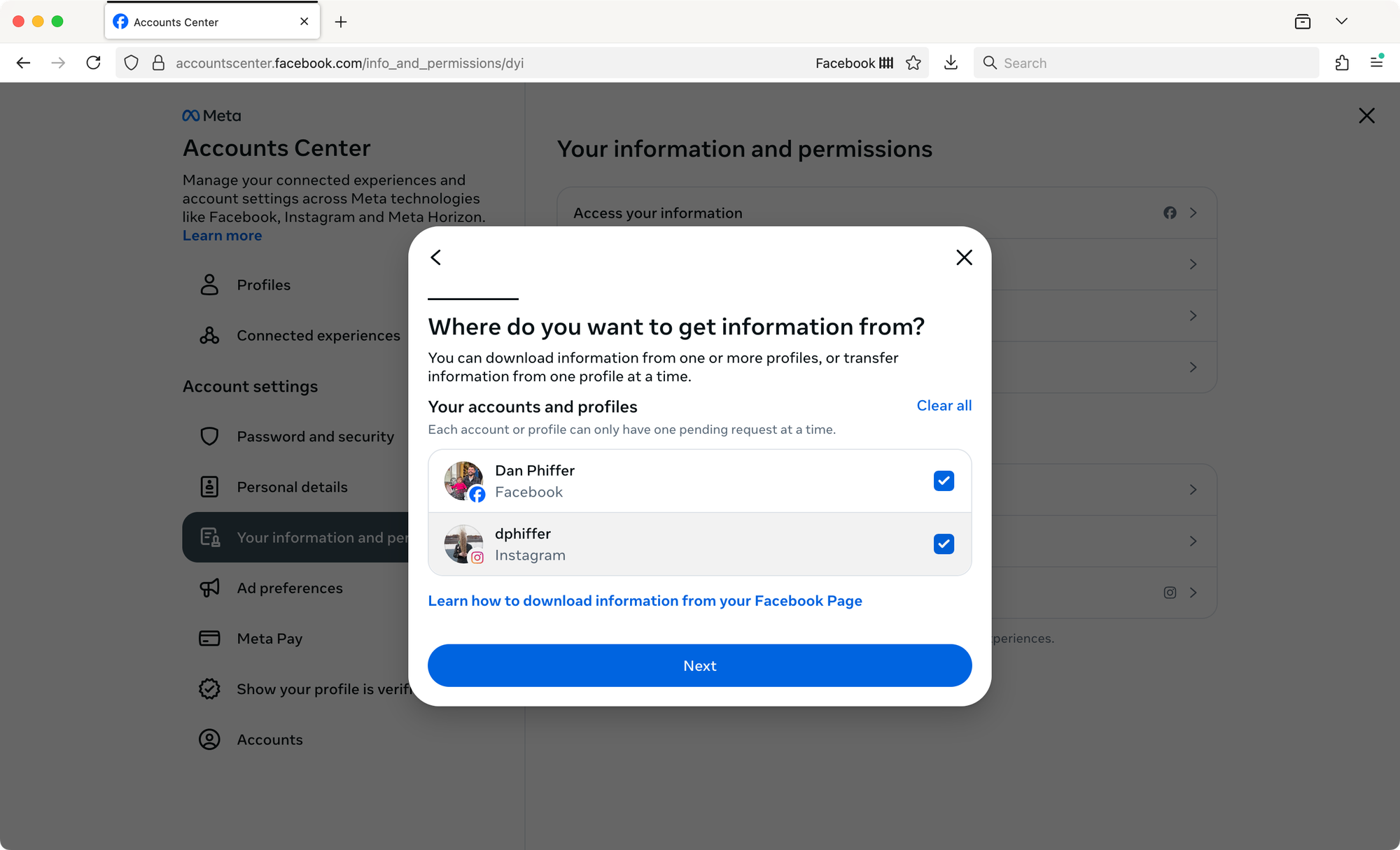
Click on Specific types of Information.
This will allow you to request your Facebook data logs, they’re not included in the Available information option.
Click Select all for each category of data.
For each account you're requesting data for (i.e., Facebook, Instagram) you'll see a bunch of categories of data you can request. You will need to press Select all several times for each category in each account to get everything.
Scroll to the bottom for each account before you press the Next button.
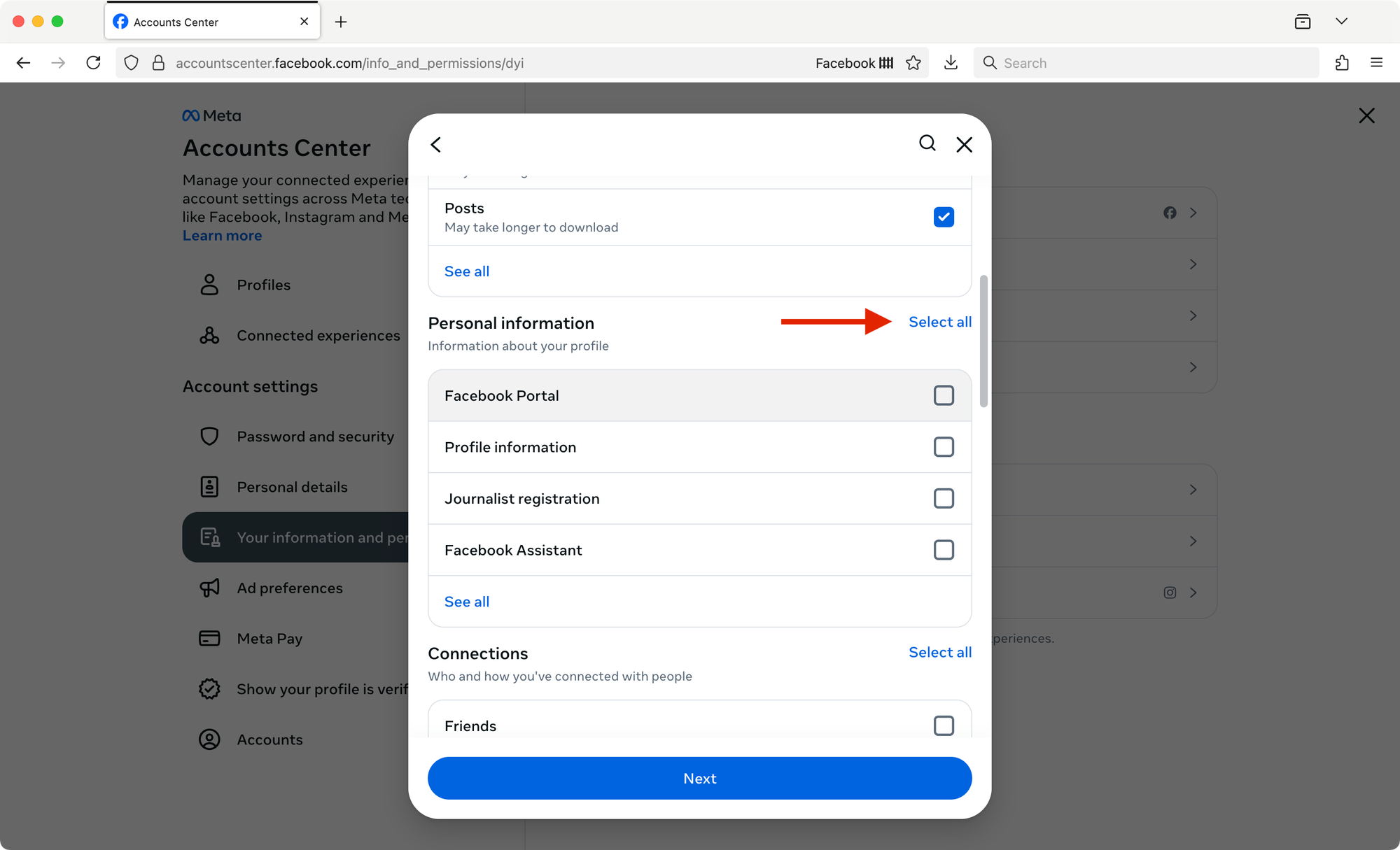
Adjust the settings for your archive file.
- Date range: All time
- Notify: your preferred email address
- Format: JSON (this will give you more flexibility working with your archive in the future)
- Media quality: High
Click the Create Files button.
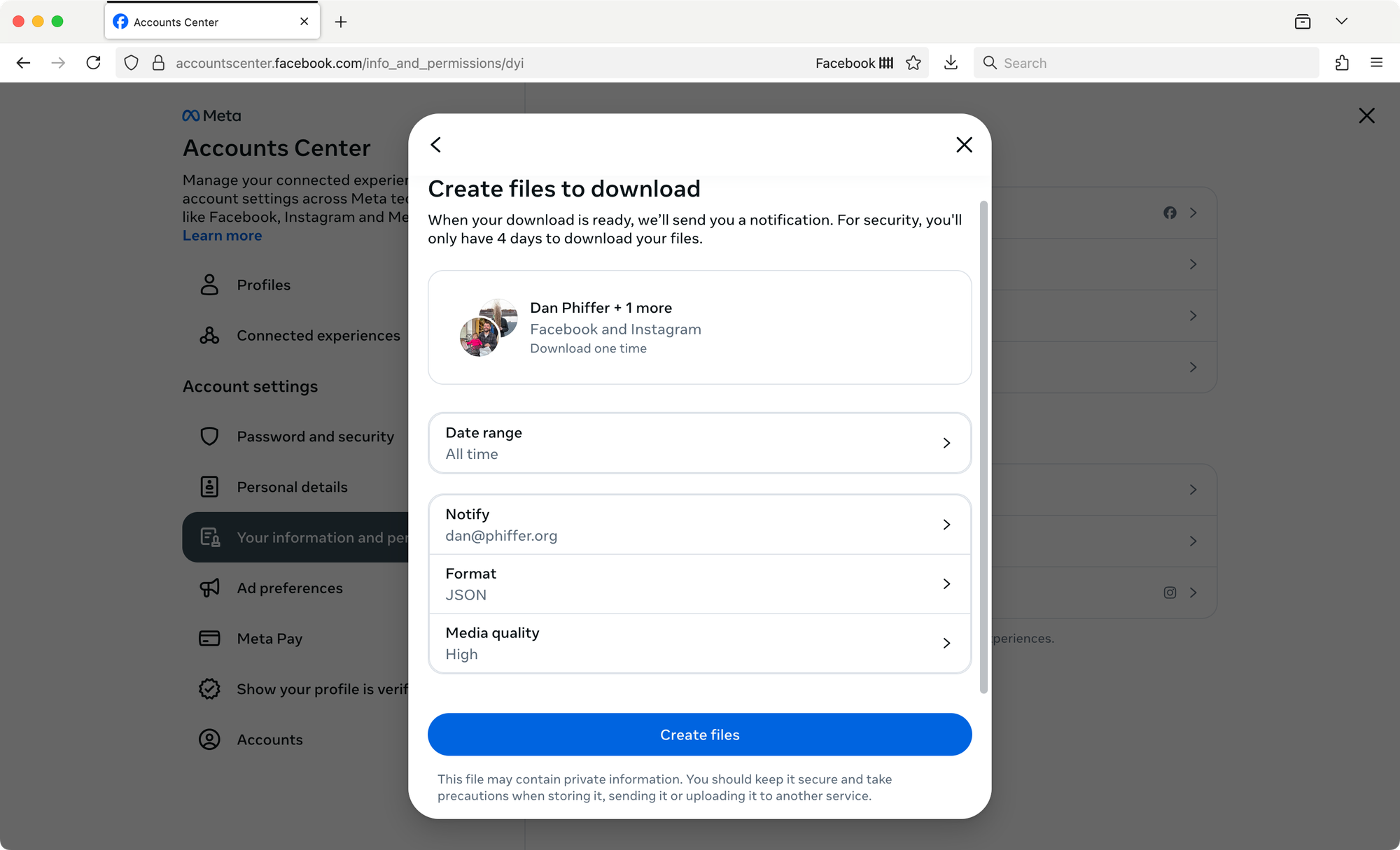
And now you wait.
You should see a message that says "You have pending downloads" under Current Activity and two different archives in progress (they separate out Facebook Data Logs as its own download). If you change your mind about some detail you can always cancel an archive request and start over again.
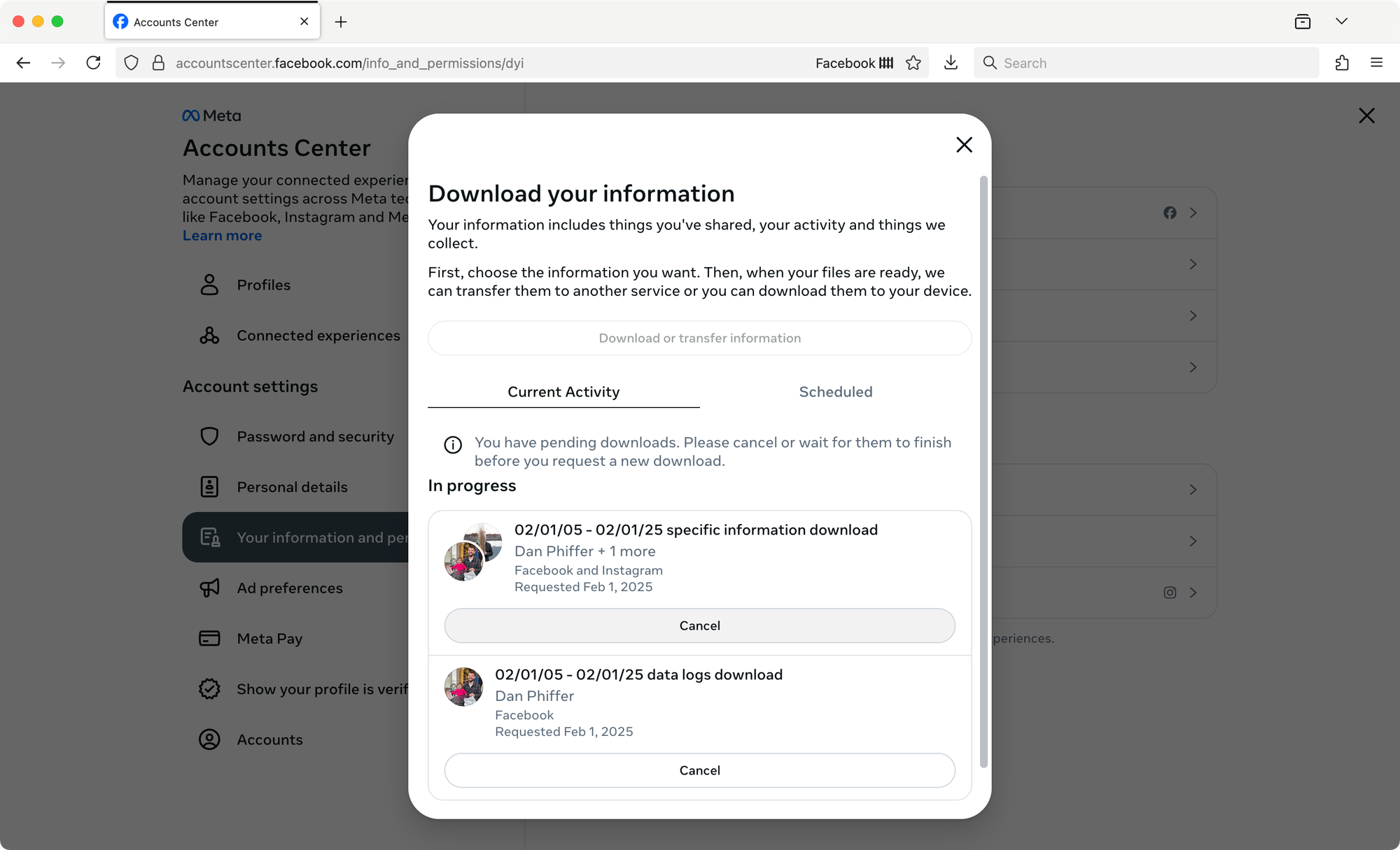
Upon submission, you should get an email with the subject line "Your Meta download request is in progress." Wait until you get another email message when your archive is ready to download.
Look for a message with the subject line Your Meta information is ready to download. Mine took a couple days to arrive.
Going back to the Download your information page will show you a new button to download your files. You may notice the data logs are not ready as quickly as the other account archives, so you'll have to wait a bit longer for those.
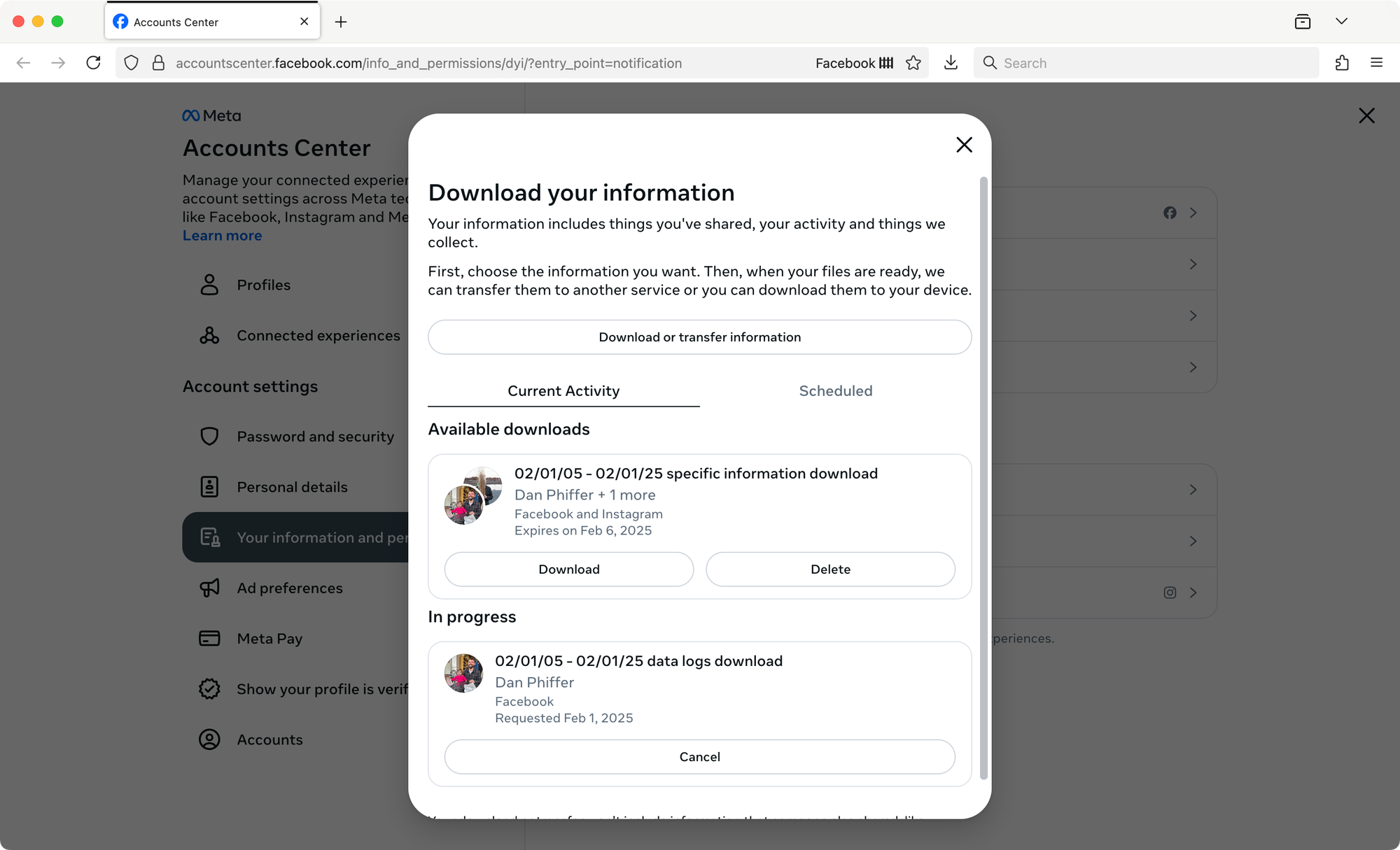
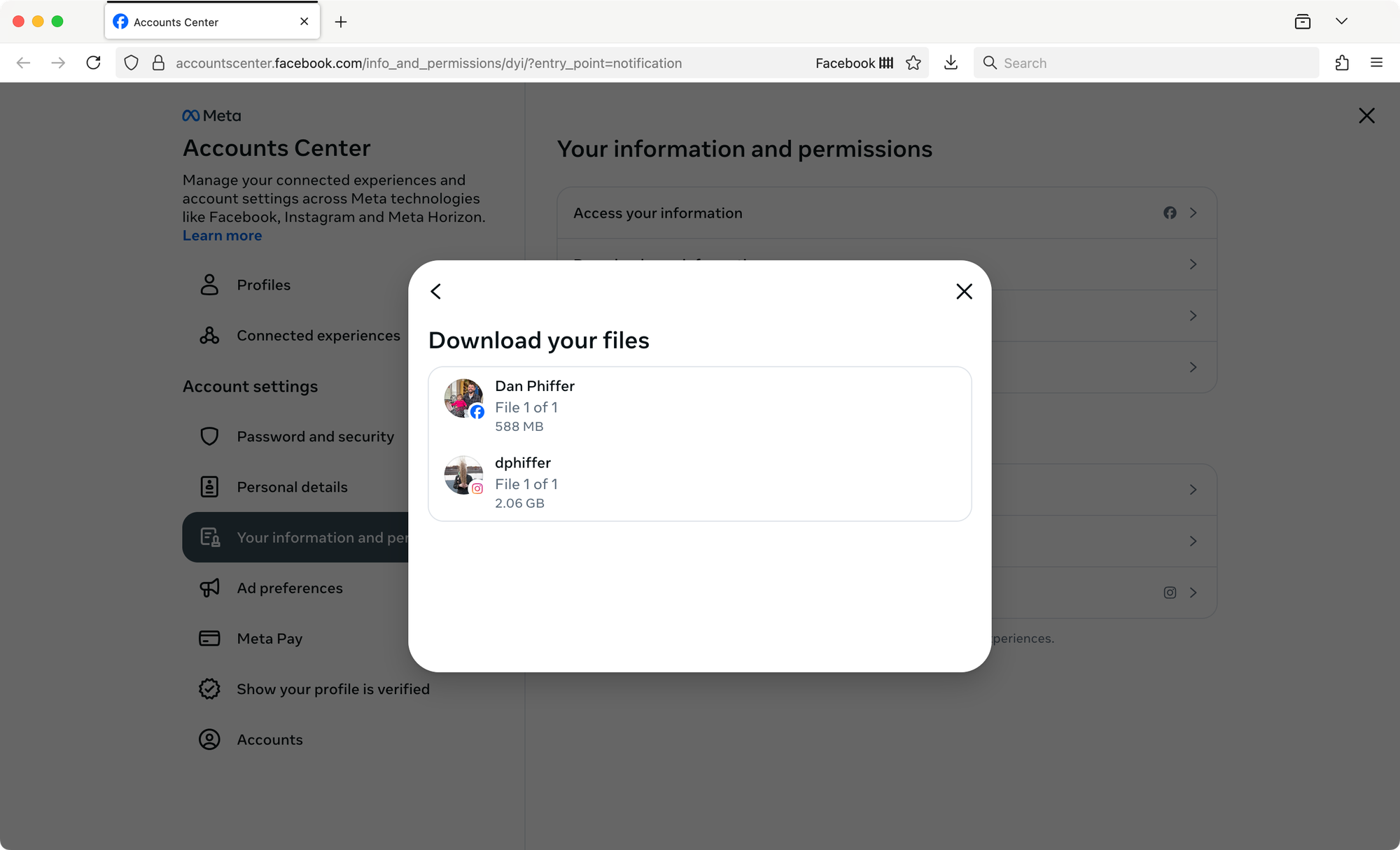
Download your files, finally!
Click on the Download button to reveal links to each of your account archives. Yes, this is what you’ve been waiting for!
Before each archive begins downloading, you’ll be prompted to enter your account password. The Instagram download option really does want your Instagram login, even though you’re on a page that looks very Facebook-y. It took me a couple tries to realize I was incorrectly offering my Facebook password.
And then what?
What do you do with this zip file of your digital life? For now, just keep it somewhere safe. The data it contains is possibly sensitive, so be careful how you store it. I do think it’s helpful to click around and see what’s in there before you delete yourself from Meta entirely.
So, what details do you get in your archived account data? There’s a lot going on in there, but it may feel like a letdown compared to what data treasures you might have been hoping for.
Here are some of the highlights of what you’ll find in the Meta archives.
- Facebook friend: each contact includes just name and timestamp. For a handful of my contacts I did see an email address included, so there must be some way to opt into making that more public than the default. Crucially, there’s no unique Facebook ID or other identifier, which is what could make it possible to reconstruct your friend network on another platform.
- Instagram contact: you get a profile URL, username, and timestamp. This is actually much better than what you can know from the Facebook friend data. There’s also a separate list of close friends, which is also a nice touch. You could theoretically reconnect with your contacts on another platform using these lists!
- Facebook posts: the main store of data for Facebook posts appears to come from a file called your_posts__check_ins__photos_and_videos_1.json, which kind of gestures at the sheer weirdness of what a Facebook post even is. But that’s just one of the files in the posts folder, there are more! (See the screengrab below.)
- Instagram content: by comparison, there is more coherency to the kinds of data you get from Instagram: posts, stories, reels, profile photos, and IGTV videos (I guess that’s what the live videos are called). And yes, you do get all your Threads content in there too, almost as an afterthought.
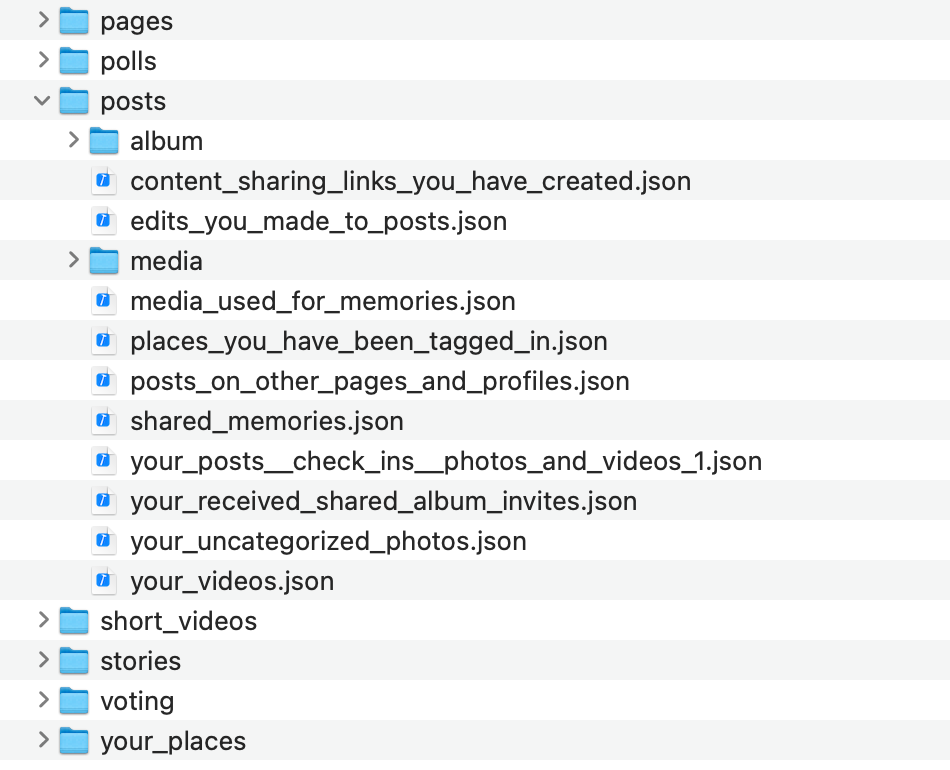
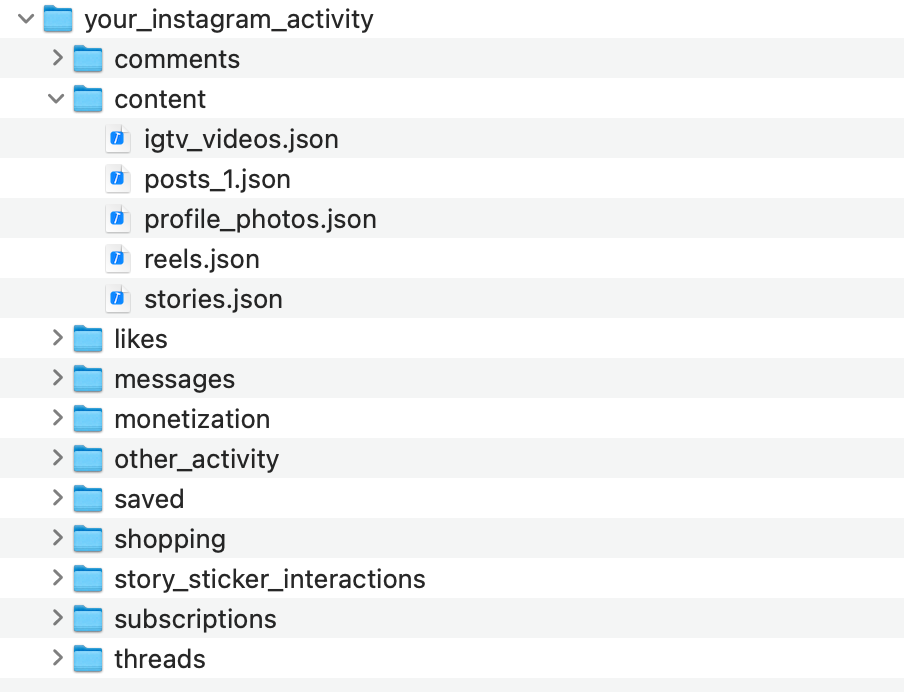
Facebook vs. Instagram posts.
There’s also all sorts of fascinating advertising-related stuff:
- advertisers_you've_interacted_with.json
- advertisers_using_your_activity_or_information.json
- your_activity_off_meta_technologies.json
- ads_viewed.json
- suggested_profiles_viewed.json
You won’t find any social interactions or metrics on your own content—no likes, shares, or comments. The archive is narrowly a collection of your stuff. But you do get a comprehensive collection of all your Facebook likes/reactions (including who posted and a timestamp) as well as all your comments (including whose post you commented on, a permalink URL, and a timestamp).
Instagram similarly has your likes (including username and permalink URLs), comments (oddly, just the comment text and whose post you were commenting on), and a file called story_likes.json. That one is simply a list of usernames whose stories you’ve liked, listed chronologically. It’s easy to imagine how these machine-readable rankings are used to decide whose posts/stories you get exposed to on the platform.
I still haven’t gotten the Data logs archive, I guess they really take a long time to generate. I’ll be curious to see what they might offer.
I have some ideas for tools I’d like to build to provide more context for the data in these JSON files and index them properly so they can be searched. Archives should be put into use, explored and referenced for future work. These static .zip archive files do not let you do much with the data, but having the data is still important.
I don’t have those archive exploration tools that I can offer you today, but maybe someday I will. And those tools will only work if you take a few minutes to download and store your account data now!